How Zyphra's TSP Cuts GPU Memory and Boosts Throughput for Large Language Models
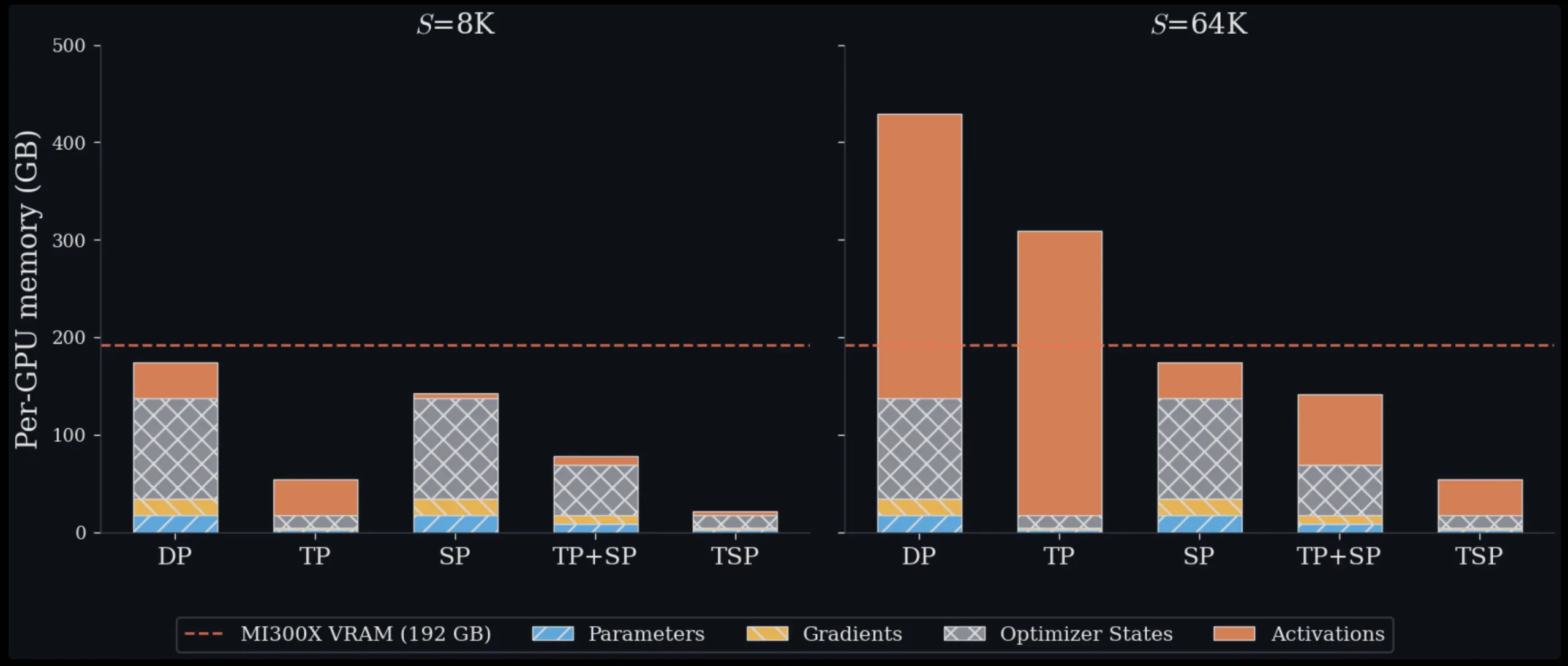
Managing memory is one of the biggest hurdles when training and deploying large transformer models. Each GPU in a cluster has a fixed amount of VRAM, and as models grow in size and handle longer sequences, engineers must constantly balance how to split the work across hardware. Zyphra, a company focusing on efficient AI infrastructure, has introduced a novel technique called Tensor and Sequence Parallelism (TSP). This approach rethinks the traditional trade-offs in parallelism, and in tests on up to 1,024 AMD MI300X GPUs, it consistently achieves 2.6x higher throughput while using less per-GPU memory than standard parallelism schemes, for both training and inference.
For more details, visit the official Zyphra blog post.
The Memory Challenge in Training Large Models
To understand why TSP matters, you first need to grasp the two parallelism strategies it combines.
Tensor Parallelism (TP)
Tensor parallelism splits model weights across multiple GPUs. For a weight matrix in an attention or MLP layer, each GPU in the TP group holds only a fraction of that matrix. This directly reduces the per-GPU memory used for parameters, gradients, and optimizer states — collectively known as model state memory. However, the trade-off is that TP requires collective communication operations (such as all-reduce or reduce-scatter/all-gather pairs) every time a layer is computed. This communication cost scales with activation size, making it increasingly expensive as sequence length grows.
Sequence Parallelism (SP)
Sequence parallelism takes a different approach. Instead of splitting weights, it splits the input token sequence across GPUs. Each GPU processes only a fraction of the tokens, which reduces activation memory and the quadratic cost of attention computation. However, SP leaves model weights fully replicated on every GPU, meaning model state memory remains unchanged regardless of how many GPUs you add to the SP group.
The Hidden Cost of Combining TP and SP
In standard multi-dimensional parallelism, engineers combine TP and SP by placing them on orthogonal axes of a device mesh. If you choose a TP degree of T and an SP degree of Σ, your model replica uses T × Σ GPUs. This incurs two significant drawbacks:
- More GPUs consumed per replica: Fewer GPUs remain available for data-parallel replicas, limiting overall throughput.
- Slow inter-node communication: When T × Σ spans multiple nodes, some collective communication must travel over slower interconnects like InfiniBand or Ethernet rather than high-bandwidth intra-node fabrics (e.g., AMD Infinity Fabric or NVIDIA NVLink).
Data parallelism (DP) avoids these model-parallel costs entirely but replicates all model state on every device, making it impractical for large models or long contexts on its own.
Introducing TSP: Folding Parallelism for Efficiency
Zyphra's TSP introduces a concept called parallelism folding. Instead of placing TP and SP on separate, orthogonal mesh dimensions, it collapses both onto a single device-mesh axis of size D. Every GPU in the TSP group simultaneously holds 1/D of the model weights and 1/D of the token sequence.
How Folding Works
By sharding both weights and sequences along the same axis, TSP eliminates the need for inter-node communication for many collective operations. The communication pattern becomes simpler and more local, often staying within a single node where bandwidth is highest. This reduces the peak memory per GPU while maintaining the benefits of both TP (smaller model state) and SP (smaller activations). The result is a more balanced workload that scales efficiently across hundreds of GPUs.
In benchmark tests on up to 1,024 AMD MI300X GPUs, TSP delivered 2.6x throughput improvement over matched TP+SP baselines while using lower per-GPU peak memory across all configurations, for both training and inference workloads.
Implications for AI Infrastructure
TSP's approach is particularly valuable for environments with limited intra-node bandwidth or when operating at very large scale. By reducing the communication overhead and memory footprint, it enables training larger models or processing longer sequences on the same hardware. It also simplifies the design of parallelism strategies, as engineers no longer need to carefully tune two separate axes.
For inference, the lower memory usage means higher throughput for serving large language models, and the simplified communication pattern reduces latency variability.
Conclusion
Zyphra's TSP represents a smart evolution in parallelism techniques for transformer models. By folding tensor and sequence parallelism onto a single dimension, it addresses the core memory and communication bottlenecks that plague large-scale training and inference. The demonstrated 2.6x throughput gain on AMD hardware suggests that this technique could become a standard tool for building and deploying next-generation AI systems. For teams investing in large GPU clusters, TSP offers a practical way to get more performance out of every GPU — without increasing cost or complexity.
Learn more about TSP and its benchmarks on the Zyphra blog.